I always thought decision trees were meant to be applied problems with categorical outcomes, but I was mistaken. Decision trees where the target variable can take continuous values are called regression trees.
[In regression tress, the] number in each leaf is the mean of the response for the observations that fall there (Introduction to Statistical Learning, p.304).
The Jupyter Notebook for this little project is found here
Dataset: Predicting House Prices
The data explored in this post is the Kaggle House Prices for Advanced Regression Techniques dataset, where the goal is to predict sales prices. But before training the regression tree, the data was first preprocessed by:
- Mapping categorical variables to numerical variables using one-hot encoding (as done in Day24)
- Removing NAs
- Splitting the data to 80% training and 20% validation
Regression tree
Once the training data is preprocessed, we can then train a regression tree with:
from sklearn import tree
clf = tree.DecisionTreeRegressor()
clf = clf.fit(X_train, y_train)
# Prediction
clf.predict(X_test)
Evaluation
Evaluating the predictions on the validation set, we get 1% prediction accuracy.
Very low.
If instead the prediction does not need to be spot on (i.e. exact), the prediction accuracy is much better.
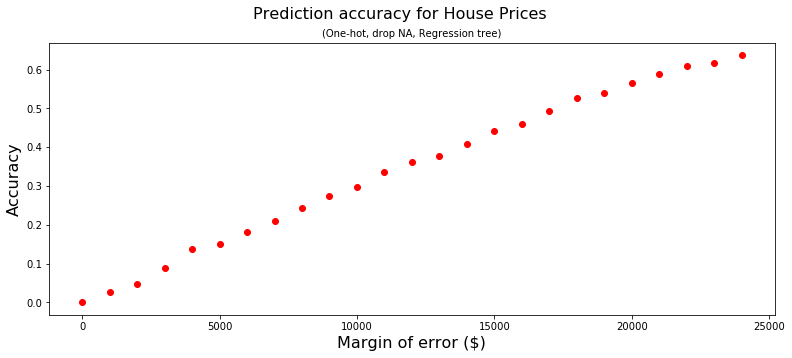
Keep in mind we have not cross validated or done any feature engineering.