Yesterday we installed Postgres, today we add in data from a dataset. The data we’ll be using is from Kaggle: Human Resources Analytics. The fields in the dataset include:

The first 5 lines of the dataset are:
satisfaction_level,last_evaluation,number_project,average_montly_hours,time_spend_company,Work_accident,left,promotion_last_5years,sales,salary
0.38,0.53,2,157,3,0,1,0,sales,low
0.8,0.86,5,262,6,0,1,0,sales,medium
0.11,0.88,7,272,4,0,1,0,sales,medium
0.72,0.87,5,223,5,0,1,0,sales,low
Creating the “hr” database
We first create the database.
initdb postgres
pg_ctl -D postgres -l logfile start
createdb hr
psql hr
Creating the table
We next create the table “survey” storing the hr information.
CREATE TABLE survey (
id serial PRIMARY KEY,
satisfaction_level numeric,
last_evaluation numeric,
number_project integer,
average_montly_hours integer,
time_spend_company integer,
work_accident boolean,
left_workplace boolean,
promotion_last_5years boolean,
sales varchar,
salary varchar
);
- Reference: PostgreSQL - Data Types
Importing the data
Single record
INSERT INTO survey (satisfaction_level, last_evaluation, number_project, average_montly_hours, time_spend_company, work_accident, left_workplace, promotion_last_5years, sales, salary) VALUES (0.38, 0.53, 2, 157, 3, '0', '1', '0', 'sales', 'low');
When we have many records, inserting one by one is somewhat laborious.
Many records in bulk with COPY
COPY survey (satisfaction_level, last_evaluation, number_project, average_montly_hours, time_spend_company, work_accident, left_workplace, promotion_last_5years, sales, salary)
FROM '/Users/csiu/repo/kaggle/hr/data/import-me.csv'
WITH CSV HEADER;
We COPY into table “survey” by specifying the columns. This makes it so that the primary key is populated with values from the sequence.
The copy command allows you to specify which columns to populate. If [we] omit the id column, it will be populated with the values from the sequence (a_horse_with_no_name, 2015)
We also indicate which file to copy FROM, and WITH what options. Option “CSV” and “HEADER” indicates the file is a comma-separated-values file and that there is header that needs to be skipped during import.
The import-me.csv file is generated as follows:
with open("import-me.csv", 'w') as out:
with open("HR_comma_sep.csv") as f:
for line in f:
line = line.strip().split(",")
line = ','.join(line[:5] + ['"'+i+'"' for i in line[5:]]) + '\n'
out.write(line)
satisfaction_level,last_evaluation,number_project,average_montly_hours,time_spend_company,"Work_accident","left","promotion_last_5years","sales","salary"
0.38,0.53,2,157,3,"0","1","0","sales","low"
0.8,0.86,5,262,6,"0","1","0","sales","medium"
0.11,0.88,7,272,4,"0","1","0","sales","medium"
0.72,0.87,5,223,5,"0","1","0","sales","low"
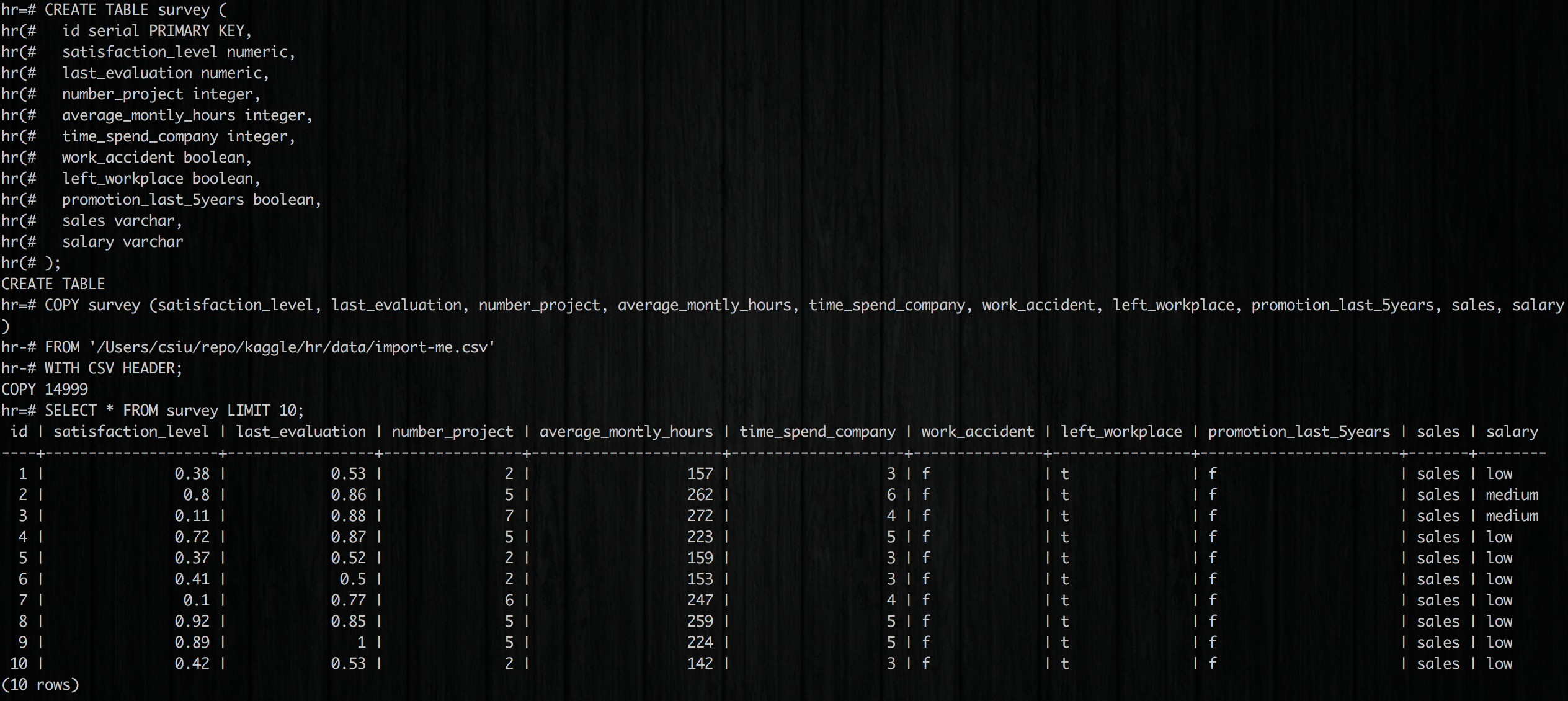
In the screenshot, we (1) created the table, (2) successfully imported 14,999 records, and (3) displayed the first 10 records.
Querying the database
Now that the data is in the database, we can make some queries. For instance, counting the number of records for the different levels of salary or the number of records for the different departments in which they work for.
hr=# SELECT salary,count(*) FROM survey GROUP BY salary;
salary | count
--------+-------
low | 7316
medium | 6446
high | 1237
(3 rows)
hr=# SELECT sales,count(*) FROM survey GROUP BY sales;
sales | count
-------------+-------
accounting | 767
technical | 2720
marketing | 858
sales | 4140
IT | 1227
management | 630
support | 2229
product_mng | 902
hr | 739
RandD | 787
(10 rows)
Summary
Overall, we created a database and imported data. In a later post, we will do something with this data.