Continuing from where I left off a couple days of ago on Day 53, I now have the , , and matrices. I now can now investigate the following question: given a document, what is the most similar document to it in the corpus.
- - document space
- - interaction between documents and words
- - words space
The Jupyter Notebook for this little project is found here. I also created a shell script to start and stop my PostgreSQL server here.
Computing distances
In text analysis, distance is generally measured by Euclidean or Cosine distances. (In this post, I used the Euclidean distance.)
Euclidean distance =
where and are 2 points; and is the number of dimensions.
To find the closest document, we look in the document space i.e. . For the pairwise comparison of all documents to all documents, my computer crashed. Best not to try that again.
from sklearn.metrics import pairwise_distances
# dist = pairwise_distances(U, U, metric='euclidean')
# dist = pairwise_distances(U, U, metric='cosine')
As a work around, we can – for a given document (“document0”) – calculate the distance between this document with every other document. Compute distance: 1 to many – yes; many to many – no.
# Look at first document
dist = pairwise_distances(np.asmatrix(U[0]), U, metric='euclidean')
Here we plot the distribution of distances to document0:
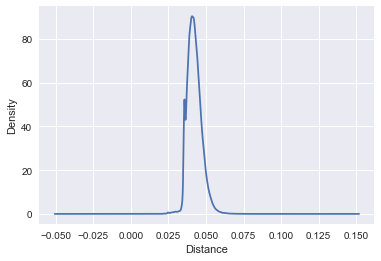
Ranking by document similarity
To find the documents most similar to document0, we sort by increasing distances and arbitrarily display the top 5 documents most similar to document0. The closest document is of course itself (sanity check passed).
# Sort by distance
top_5 = df_dist.sort_values("distance").head()
| distance | |
|---|---|
| 0 | 6.585445e-10 |
| 131582 | 1.690946e-02 |
| 131258 | 1.705223e-02 |
| 129792 | 1.722522e-02 |
| 159369 | 1.842629e-02 |
Mapping from indexes to Kickstarter projects
The indexes of the above matrices match the Kickstarter project files that were previously created in Day 50. After loading the original and preprocessed Kickstarter project data, we can then use the indexes to obtain the similar projects.
for index, row in df.iloc[top_5.index].iterrows():
original_text = df_original[df_original['id'] == row['id']].iloc[0]['document']
print('>> %s | %s' % (row['id'], row['document']),
original_text, "\n", sep="\n")
>> 1312331512 | fulli develop anim seri requir profession anim first homeanim ep onlin
We have a fully developed 2D animated series that requires more professional animation. Our first 2 home-animated eps are up online.
>> 1939908068 | hamstrong anim seri hamster mission escap anim test laboratori
Hamstrong is an animated series about a hamster on a mission to escape an animal testing laboratory.
>> 542664697 | never watch anim challeng watch seri anim non stop intend document crazi happen
I have never watched anime and I have been challenged to watch 10 series of anime non stop. I intend to document the crazy that happens
>> 74332521 | detroit farm anim seri farm anim daili struggl grow urban area detroit mi
Detroit Farm is an animated series about farm animals and their daily struggles of growing up in an urban area such as Detroit, MI.
>> 1672120020 | hope kickstart anim career new anim seri
This is to (hopefully) 'kickstart' my animation career and a new animated series.
Looking good – all projects are about anime!