Another approach for improving the predictions resulting from a decision tree is Boosting.
The Jupyter Notebook for this little project is found here.
Boosting
In boosting, trees are grown sequentially. This means learning depends strongly on trees that already have been grown. According to the Introduction to Statistical Learning (p.321 “Boosting”), Boosting does not involve bootstrap sampling; instead each tree is fit on a modified version of the original data set.
In Scikit-learn, a popular boosting algorithm “AdaBoost” is called using sklearn.ensemble.AdaBoostClassifier.

from sklearn.ensemble import AdaBoostClassifier
boost = AdaBoostClassifier(n_estimators=100, learning_rate=0.01, random_state=1)
boost = boost.fit(X_train, y_train)
Tuning the boosting algorithm
With regards to parameters, Boosting has 3:
- Number of trees (too many => overfit)
- Shrinkage parameter (~learning rate)
- Number of splits in tree (~complexity of model; weak learners okay)
# Try these parameters
number_of_trees = [25, 50, 100, 200]
learning_rate = [1, 0.1, 0.01, 0.001]
When we varied the number_of_trees and learning_rate of the boosting algorithm on the Kaggle House Prices for Advanced Regression Techniques dataset as described on Day93, we found that:
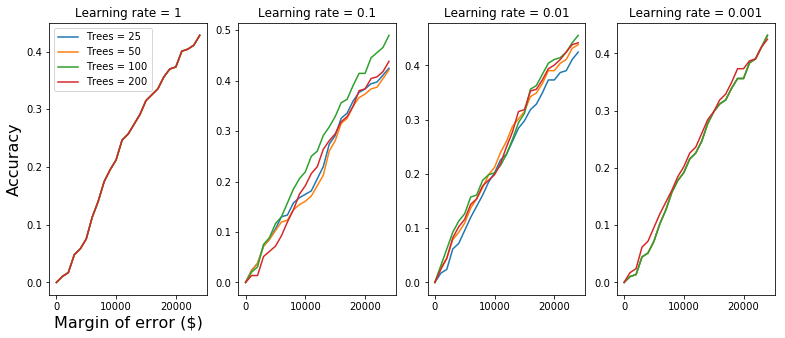
- more trees => better predictors
- low learning rates => slow learning => poor predictors [Right panel]
- high learning rates => learning not precise => poor predictors [Left panel]
Sweet spot is in between.