Another procedure I heard about is bagging.
The Jupyter Notebook for this little project is found here.
Bagging
According to wikipedia, bagging stands for stands for “bootstrap aggregating”, a special case of model averaging designed to improve stability and accuracy & reduce reduce variability and overfitting. Bagging is applied by:
- Generating a “bootstrap sample” by sampling with replacement (where the number of samples in the bootstrap sample is equal to the number of samples in the original dataset)
- Constructing a regression tree from the bootstrap sample
- Repeating steps 1-2 to get
Bregression trees - Combining the
Boutputs by averaging (for regression) or voting (for classification)
In python, bagging can be specified using Scikit-learn’s sklearn.ensemble.BaggingClassifier function.
from sklearn.ensemble import BaggingClassifier
clf = BaggingClassifier()
clf = clf.fit(X_train, y_train)
Predicting on the House Prices dataset
Using the same Kaggle House Prices for Advanced Regression Techniques dataset as described yesterday (Day93), the prediction accuracy is comparable.
Yesterday’s
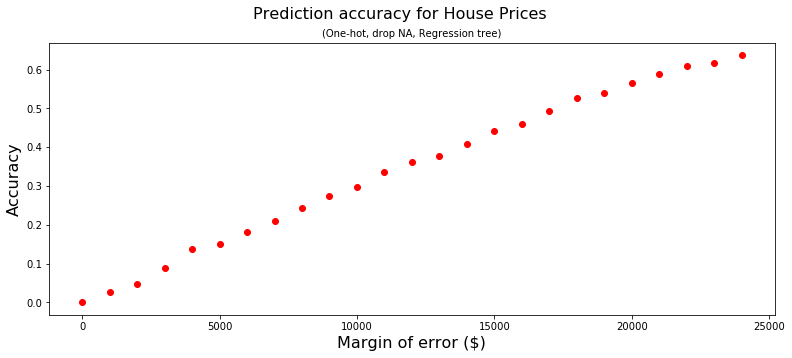
Today’s
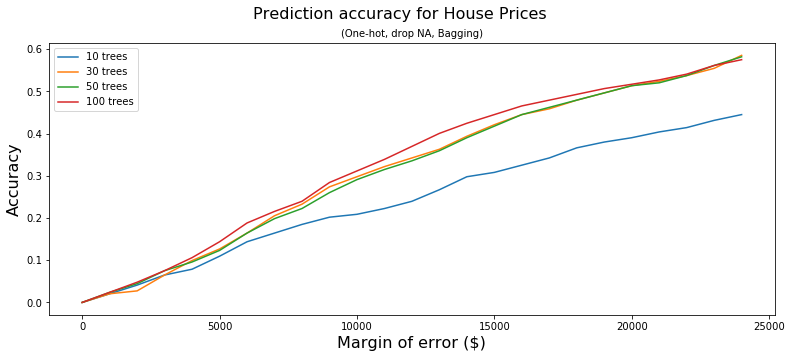
In the bagging methods, we also see that (up to a point) more trees results to higher accuracy.